


Jun
29

一直觉得C++做到了一件看似不可能的任务:
实现了完整的OO(甚至还有多继承),同时提供了对泛型几近完美的支持,还保证了足够的效率。
相比之下,
Java对OO的支持的确很好,但是它对泛型的支持,我觉得只能用丑陋来形容;同时它还提供了让我难以接受的效率。
Sandy在用Java开发他的手机游戏时就遇到了种种问题,
我也无法接受它"把一切都封装好只为让开发更简单"这样的Bullshit。
事实上一切都变复杂了。
C没有提供对OO的支持,也没有提供对泛型的直接支持;效率的确可观,但是用于开发,似乎很费劲。
对于开发人员,为一个安全数组写一大段基于malloc/realloc和需要强制类型的转换的代码似乎很累,而且可读性也差。
而C++的vector使用起来就相当省事,代码也更加清晰易读。
所以曾经有一段时间感到有点纳闷,为什么那么多大项目是用C开发的,而不是C++?
"历史遗留问题"似乎解释不通,比如Linux源代码是经过了几次完全的重写,其间C++已经发展得比较完善了。
回过头来想想另一件事情:
如果你经常逛一些偏开发类的论坛(比如CSDN?),并看到过那些有"纯正血统"的Java程序员的言论
你就会知道那些人如同不学无术的八旗子弟一般不堪;
尤其是他们对指针的理解,那根本就是P话,而且一点都不好笑。
这里不是想嘲笑他们有多么粗俗浅陋,毕竟没有学C不一定是他们的错。
这只是个类比,C和C++的对比,在一些方面与C/C++和Java的对比还是很相似的。
Linux之父Linus对C++嗤之以鼻,甚至因此和某人大吵一架,并毫不保留地表达了他对C++以及C++程序员的蔑视。
从普通开发者的角度看来,一个提供完整OOP支持的语言不仅提高了开发效率、增加代码可读性,还为代码重用带来了极大的便利。这的确是现代大型系统开发需要的,但是它真的做到了吗?
你在学习C++的过程中可以很容易的学到如何继承一个类,可是你知道如果这个类的析构函数不是虚函数可能带来怎样的后果?你可以很容易地学到如何使用set/map,如何为它写一个简单的functor,可是你知道严格弱序化这个原则吗(Strict Weak Ordering)?
如果你不知道,没关系,这不是你的错,因为C++已经复杂到让人吃惊的地步了:STL中出现的traits和可以重载的逗号运算符都不算什么了,可是居然还能有boost这么变态的东西!甚至有人说,C++是唯一一门连语言之父都要别人教他怎么使用的语言了。
从某些角度来说,Java似乎做得更好:提供了丰富的类库以及完善的GC,你忘记了的东西通通交给它吧----可是你真的放心么?如果你知道Sandy仅仅因为String的问题就纠结了那么久,你就不会给出肯定答案了。我的看法是,Java只是把一切都变得复杂了(的确,我对Java有偏见,Sandy也是)。
最后回到C。不可否认,C标准库里的东西太少了,和现实不够接轨,不是类型安全的,只有指针没有引用也让代码看起来更ooxx... 但是仔细想想,其实C提供了一个足够简洁而完善的对底层的合理抽象,将控制一切的操作能力都交给你,让你能够不纠结于语言层面的复杂性,而将精力投入到功能的实现中去。
不要认为C不支持面向对象,不要认为这一点就限制了设计模式的使用----事实上,完全用C写就的Linux源代码是高度面向对象的,使用了令人惊叹的设计模式,达到了不可思议的效率和可扩展性。
做了这样的对比,不是想说C++和Java有多么不堪,至少从进化论的角度来说,他们都是成功的、优秀的。仔细思索,之所以Linus如此鄙视C++,并不是因为C++真的很差,而是因为C++的复杂性使得系统的设计变得更加复杂(特别是在要求高效率的地方,你用C++可能根本找不到效率损失于何处!),更为可怕的是,有那么多自以为是的程序员,以为学会了class a: public b就是学会了面向对象,以为学会了Observer模式的含义就真正掌握了设计模式,甚至以为学会了MFC就是学会了C++。如果这些人加入Linux内核的开发,那的的确确是一场灾难,而且极其可怕。
"的确有不少C++程序员贡献代码,但是反而需要核心的C程序员花费更多时间去修改和删除。"
最后,援引Linus的一句话作为结束:
实现了完整的OO(甚至还有多继承),同时提供了对泛型几近完美的支持,还保证了足够的效率。
相比之下,
Java对OO的支持的确很好,但是它对泛型的支持,我觉得只能用丑陋来形容;同时它还提供了让我难以接受的效率。
Sandy在用Java开发他的手机游戏时就遇到了种种问题,
我也无法接受它"把一切都封装好只为让开发更简单"这样的Bullshit。
事实上一切都变复杂了。
C没有提供对OO的支持,也没有提供对泛型的直接支持;效率的确可观,但是用于开发,似乎很费劲。
对于开发人员,为一个安全数组写一大段基于malloc/realloc和需要强制类型的转换的代码似乎很累,而且可读性也差。
而C++的vector使用起来就相当省事,代码也更加清晰易读。
所以曾经有一段时间感到有点纳闷,为什么那么多大项目是用C开发的,而不是C++?
"历史遗留问题"似乎解释不通,比如Linux源代码是经过了几次完全的重写,其间C++已经发展得比较完善了。
回过头来想想另一件事情:
如果你经常逛一些偏开发类的论坛(比如CSDN?),并看到过那些有"纯正血统"的Java程序员的言论
你就会知道那些人如同不学无术的八旗子弟一般不堪;
尤其是他们对指针的理解,那根本就是P话,而且一点都不好笑。
这里不是想嘲笑他们有多么粗俗浅陋,毕竟没有学C不一定是他们的错。
这只是个类比,C和C++的对比,在一些方面与C/C++和Java的对比还是很相似的。
Linux之父Linus对C++嗤之以鼻,甚至因此和某人大吵一架,并毫不保留地表达了他对C++以及C++程序员的蔑视。
引用
...(Git)项目限制只用C,意味着参与的人不会捣乱,也意味着会得到许多真正懂得底层问题,而不会折腾那些白痴‘对象模型’垃圾的程序员。...所以,我很抱歉,但是对于Git这样效率是主要目标的软件,C++的所谓优点只是巨大的错误。而我们将看不到这一点的人排除在外却成了一个巨大的附加优势。...
你在学习C++的过程中可以很容易的学到如何继承一个类,可是你知道如果这个类的析构函数不是虚函数可能带来怎样的后果?你可以很容易地学到如何使用set/map,如何为它写一个简单的functor,可是你知道严格弱序化这个原则吗(Strict Weak Ordering)?
如果你不知道,没关系,这不是你的错,因为C++已经复杂到让人吃惊的地步了:STL中出现的traits和可以重载的逗号运算符都不算什么了,可是居然还能有boost这么变态的东西!甚至有人说,C++是唯一一门连语言之父都要别人教他怎么使用的语言了。
从某些角度来说,Java似乎做得更好:提供了丰富的类库以及完善的GC,你忘记了的东西通通交给它吧----可是你真的放心么?如果你知道Sandy仅仅因为String的问题就纠结了那么久,你就不会给出肯定答案了。我的看法是,Java只是把一切都变得复杂了(的确,我对Java有偏见,Sandy也是)。
最后回到C。不可否认,C标准库里的东西太少了,和现实不够接轨,不是类型安全的,只有指针没有引用也让代码看起来更ooxx... 但是仔细想想,其实C提供了一个足够简洁而完善的对底层的合理抽象,将控制一切的操作能力都交给你,让你能够不纠结于语言层面的复杂性,而将精力投入到功能的实现中去。
不要认为C不支持面向对象,不要认为这一点就限制了设计模式的使用----事实上,完全用C写就的Linux源代码是高度面向对象的,使用了令人惊叹的设计模式,达到了不可思议的效率和可扩展性。
做了这样的对比,不是想说C++和Java有多么不堪,至少从进化论的角度来说,他们都是成功的、优秀的。仔细思索,之所以Linus如此鄙视C++,并不是因为C++真的很差,而是因为C++的复杂性使得系统的设计变得更加复杂(特别是在要求高效率的地方,你用C++可能根本找不到效率损失于何处!),更为可怕的是,有那么多自以为是的程序员,以为学会了class a: public b就是学会了面向对象,以为学会了Observer模式的含义就真正掌握了设计模式,甚至以为学会了MFC就是学会了C++。如果这些人加入Linux内核的开发,那的的确确是一场灾难,而且极其可怕。
"的确有不少C++程序员贡献代码,但是反而需要核心的C程序员花费更多时间去修改和删除。"
最后,援引Linus的一句话作为结束:
引用
C最大的优点之一,就是它不会使你认为程序是什么高层的东西。
Jun
23
坦白说,我不确定这个东西是不是叫做败者树,因为我觉得它就是以前写过n遍的线段树的一个简单变种。
在线段树的每个节点存储v, i,分别表示该区间内最小值和最小值所在单元的索引。
建立好线段树以后,每次取出整个区间的最小值,然后将该值来源的那一路的下一个数字填充进去
如果那一路已经没有下一个数字了,就填一个max进去,然后递归地更新其所有祖先节点。
这个过程有点像heap的sift_up。
代码如下:
在线段树的每个节点存储v, i,分别表示该区间内最小值和最小值所在单元的索引。
建立好线段树以后,每次取出整个区间的最小值,然后将该值来源的那一路的下一个数字填充进去
如果那一路已经没有下一个数字了,就填一个max进去,然后递归地更新其所有祖先节点。
这个过程有点像heap的sift_up。
代码如下:
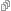
Jun
23
一般数据结构上用败者树来实现,这东西我没写过,所以暂时忽略之。
改用相对比较熟悉的heap来处理,写了一个class heap。
为了方便采用一个 5 x 5 的数组来存储需要归并的数据;很容易可以扩展到不定长的不同数据组。
明天再试着写一下败者树。
代码如下:
改用相对比较熟悉的heap来处理,写了一个class heap。
为了方便采用一个 5 x 5 的数组来存储需要归并的数据;很容易可以扩展到不定长的不同数据组。
明天再试着写一下败者树。
代码如下:
Jun
21
话说,虽然felixoj的judge已经在几天前完工,
但是有一个地方是felix没有理解的(因为是copy的sempr大牛的hustoj的流程):
按理,当RE/OLE的时候child是会收到SIGSEGV/SIGFPE...等表示RE的信号,或者SIGXFSZ表示OLE的信号
但是在wait4以后WIFSIGNALED(status)并没有得到正确的结果。
Sempr大牛的版本是另做了一些处理:
对此感到非常难以理解,于是咨询Sempr大牛。
大牛以其强悍的记忆力回忆一年前的事情,大致的回复是
status >> 8 差不多是EXITCODE
sig == 5 差不多是正常暂停
于是广搜资料,获得了一些更详细的信息:
WIFSIGNALED: 如果进程是被信号结束的,返回True
WTERMSIG: 返回在上述情况下结束进程的信号
WIFSTOPPED: 如果进程在被ptrace调用监控的时候被信号暂停/停止,返回True
WSTOPSIG: 返回在上述情况下暂停/停止进程的信号
另 psignal(int sig, char *s),进行类似perror(char *s)的操作,打印 s, 并输出信号 sig 对应的提示,其中
sig = 5 对应的是 Trace/breakpoint trap
sig = 11 对应的是 Segmentation fault
sig = 25 对应的是 File size limit exceeded
于是问题就解决了。
最后我的判断条件是:
另外用 strsignal(int sig) 函数获得 信号sig 对应的描述文字并用fprintf(stderr, "%s", 这样的语句输出。
但是有一个地方是felix没有理解的(因为是copy的sempr大牛的hustoj的流程):
按理,当RE/OLE的时候child是会收到SIGSEGV/SIGFPE...等表示RE的信号,或者SIGXFSZ表示OLE的信号
但是在wait4以后WIFSIGNALED(status)并没有得到正确的结果。
Sempr大牛的版本是另做了一些处理:
int sig = status >> 8;
if(sig == 5);
else{
switch(sig){
case SIGSEGV: ...
case SIGXFSZ: ...
...
}
}
if(sig == 5);
else{
switch(sig){
case SIGSEGV: ...
case SIGXFSZ: ...
...
}
}
对此感到非常难以理解,于是咨询Sempr大牛。
大牛以其强悍的记忆力回忆一年前的事情,大致的回复是
status >> 8 差不多是EXITCODE
sig == 5 差不多是正常暂停
于是广搜资料,获得了一些更详细的信息:
WIFSIGNALED: 如果进程是被信号结束的,返回True
WTERMSIG: 返回在上述情况下结束进程的信号
WIFSTOPPED: 如果进程在被ptrace调用监控的时候被信号暂停/停止,返回True
WSTOPSIG: 返回在上述情况下暂停/停止进程的信号
另 psignal(int sig, char *s),进行类似perror(char *s)的操作,打印 s, 并输出信号 sig 对应的提示,其中
sig = 5 对应的是 Trace/breakpoint trap
sig = 11 对应的是 Segmentation fault
sig = 25 对应的是 File size limit exceeded
于是问题就解决了。
最后我的判断条件是:
if(WIFSIGNALED(status) ||
(WIFSTOPPED(status) && WSTOPSIG(status) != 5))
(WIFSTOPPED(status) && WSTOPSIG(status) != 5))
另外用 strsignal(int sig) 函数获得 信号sig 对应的描述文字并用fprintf(stderr, "%s", 这样的语句输出。
Jun
18
@ 20091020 一直忘了补充一下,这个oj还是有问题的。
大概从什么时候开始,想写一个自己的OJ?
应该是从snoopy的flood开始的事情吧。
看了他的毕设论文,了解了一些该了解的东西。
然后我把马陈原来就很ooxx的web那一块的代码修改得更ooxx
然后flood终于不能再用了,决定回oak
可是snoopy把服务器重装了,oak的judge和daemon都没了
幸而不知道从什么地方找出了一个很ooxx的judge
虽然编译都不能通过,但是大体框架还在
于是就把那个judge看了过去,改来改去终于可以运行了
再修正一些BUG,judge总算是可以用了
然后再用java重写了一个daemon,终于把oak架起来。
在这个过程中发现很多问题,于是萌生了自己写OJ的想法。
最近这些天看了很多Linux开发的书
学会了包括wait, ptrace, setrlimit, setitimer等系统调用
----虽然以前都知道有这些东西,但是一直没有去写过
于是终于觉得量变到点了,该质变了
再加上还有sempr大牛的hustoj,节省了许多时间(syscall的列表...)
于是就在一天内写出了这个800行的judge
或者也可以说是copy sempr的judge吧,因为judge的整个流程基本一样。
写这个judge之前我已经思考了很多东西了,重点是架构的设计
我希望把judge设计成一个完全独立的程序,只负责跑程序,判输出
可惜由于RF的问题,judge还是没法和语言独立开来。
但是总的来说,这个judge和我接触过的oj的设计都不一样
它不负责任何与数据库有关的东西,只做该它做的事情
这样的好处是实现起来更加简单
由于其独立性,还可以配合不同的front-end,实现不同的judge
比如设计一个Personal版的,不需要web和daemon
这样可以进行offline judge,让acmer知道程序跑得是否正确,时间内存使用如何...
目前的这个效果是比较令我满意的,完成了一个judge该有的功能,包括spj。
felixoj(这个名字很挫吧。。。)的其他部分
比如Web, DB, Daemon, JudgeWrapper暂时没有时间去做了
预计留在暑假慢慢实现
如果你有兴趣测试使用这个judge,可以到felixoj的google code主页去:
http://felixoj.googlecode.com
大概从什么时候开始,想写一个自己的OJ?
应该是从snoopy的flood开始的事情吧。
看了他的毕设论文,了解了一些该了解的东西。
然后我把马陈原来就很ooxx的web那一块的代码修改得更ooxx
然后flood终于不能再用了,决定回oak
可是snoopy把服务器重装了,oak的judge和daemon都没了
幸而不知道从什么地方找出了一个很ooxx的judge
虽然编译都不能通过,但是大体框架还在
于是就把那个judge看了过去,改来改去终于可以运行了
再修正一些BUG,judge总算是可以用了
然后再用java重写了一个daemon,终于把oak架起来。
在这个过程中发现很多问题,于是萌生了自己写OJ的想法。
最近这些天看了很多Linux开发的书
学会了包括wait, ptrace, setrlimit, setitimer等系统调用
----虽然以前都知道有这些东西,但是一直没有去写过
于是终于觉得量变到点了,该质变了
再加上还有sempr大牛的hustoj,节省了许多时间(syscall的列表...)
于是就在一天内写出了这个800行的judge
或者也可以说是copy sempr的judge吧,因为judge的整个流程基本一样。
写这个judge之前我已经思考了很多东西了,重点是架构的设计
我希望把judge设计成一个完全独立的程序,只负责跑程序,判输出
可惜由于RF的问题,judge还是没法和语言独立开来。
但是总的来说,这个judge和我接触过的oj的设计都不一样
它不负责任何与数据库有关的东西,只做该它做的事情
这样的好处是实现起来更加简单
由于其独立性,还可以配合不同的front-end,实现不同的judge
比如设计一个Personal版的,不需要web和daemon
这样可以进行offline judge,让acmer知道程序跑得是否正确,时间内存使用如何...
目前的这个效果是比较令我满意的,完成了一个judge该有的功能,包括spj。
felixoj(这个名字很挫吧。。。)的其他部分
比如Web, DB, Daemon, JudgeWrapper暂时没有时间去做了
预计留在暑假慢慢实现
如果你有兴趣测试使用这个judge,可以到felixoj的google code主页去:
http://felixoj.googlecode.com
Jun
16
zz from http://c-faq-chn.sourceforge.net/ccfaq/node206.html#q:12.17
13.15 当我用 "%d\n" 调用 scanf 从键盘读取数字的时候, 好像要多输入一行函数才返回。
可能令人吃惊, \n 在 scanf 格式串中不表示等待换行符, 而是读取并放弃所有的空白字符
@2oo911o8
前些天试了一下,其实所谓\n代表所有空白字符,倒不如说scanf将所有空白字符等同视之:
在这里你用scanf(" "); scanf("\t");效果都是一样的。
13.15 当我用 "%d\n" 调用 scanf 从键盘读取数字的时候, 好像要多输入一行函数才返回。
可能令人吃惊, \n 在 scanf 格式串中不表示等待换行符, 而是读取并放弃所有的空白字符
@2oo911o8
前些天试了一下,其实所谓\n代表所有空白字符,倒不如说scanf将所有空白字符等同视之:
在这里你用scanf(" "); scanf("\t");效果都是一样的。
Jun
14
nth element, 也就是要找出一个数列中排名第n的那个数。
很直观地,把所有的数排序以后,就可以得出这nth element了。
快排测试:4.5s,1千万个int。
仔细想一下,这似乎有点浪费:其实只要找出最大的n个就行了。
如果n比较小,我们可以直接用选择排序。
这个程序太简单了,懒得测试。
然后再仔细想一下,发现还是有点浪费,其实前n个数不需要排序。
于是可以用最小堆来实现。
测试结果:3.02s,1千万个int,n = 500。
然后你可能会发现,STL里面有个函数,叫做nth_element,就是用来做这个的
测试一下:3.4s,1千万个int, n = 500。
如果想要深入了解,那么实际上这个nth_element使用的算法是快速划分。
它其实就是不完全的快速排序,只要递归地排序需要排序的部分就可以了。
自写代码测试:3.4s,1千万个int, n = 500。
------
从上面可以看出,在k=500(N = 10,000,000)时,最小堆是最快的,其次是快速划分,快排当然最慢。
最小堆的时间复杂度是 O( N * log(k) )
快速划分虽然平均时间复杂度是O(C*N)(但是C比较大),但是最坏时间复杂度是O(N^2)(所以随机化很重要!可以避免RPWT!)
快排就不用说了,撑死 O(N * log(N) ),最坏时间复杂度也可能是O(N^2)。
似乎最小堆是最快的,快速划分慢些,但是它们各有自己的适用范围:
当 k 接近 N / 2时,最小堆的时间复杂度其实就相当于一个堆排,事实上还不如快排。
所以最小堆的适用范围是k << N时的情况,或者当k 很接近N, 可以转化成 N-k << N的情况。
而快速划分的算法本身决定了其复杂度和 k 的大小无关,所以当 k 接近 N/2 时,快速划分显然更优。
可是还有另一种情况,也是大公司面试的时候很可能会问到的题目:
给你200亿个整数,找出TOP500000。
第一次遇到这个问题,估计大多数人直接口突白沫了吧。
200亿,对一般PC而言,内存显然存不下,需要保存在辅存中,而辅存的IO速度。。。
所以你应该尽可能少地扫描。
于是这时候最小堆就是最优解决方案:只扫描一遍,就可以得出结果。
------
代码如下:
很直观地,把所有的数排序以后,就可以得出这nth element了。
快排测试:4.5s,1千万个int。
仔细想一下,这似乎有点浪费:其实只要找出最大的n个就行了。
如果n比较小,我们可以直接用选择排序。
这个程序太简单了,懒得测试。
然后再仔细想一下,发现还是有点浪费,其实前n个数不需要排序。
于是可以用最小堆来实现。
测试结果:3.02s,1千万个int,n = 500。
然后你可能会发现,STL里面有个函数,叫做nth_element,就是用来做这个的
测试一下:3.4s,1千万个int, n = 500。
如果想要深入了解,那么实际上这个nth_element使用的算法是快速划分。
它其实就是不完全的快速排序,只要递归地排序需要排序的部分就可以了。
自写代码测试:3.4s,1千万个int, n = 500。
------
从上面可以看出,在k=500(N = 10,000,000)时,最小堆是最快的,其次是快速划分,快排当然最慢。
最小堆的时间复杂度是 O( N * log(k) )
快速划分虽然平均时间复杂度是O(C*N)(但是C比较大),但是最坏时间复杂度是O(N^2)(所以随机化很重要!可以避免RPWT!)
快排就不用说了,撑死 O(N * log(N) ),最坏时间复杂度也可能是O(N^2)。
似乎最小堆是最快的,快速划分慢些,但是它们各有自己的适用范围:
当 k 接近 N / 2时,最小堆的时间复杂度其实就相当于一个堆排,事实上还不如快排。
所以最小堆的适用范围是k << N时的情况,或者当k 很接近N, 可以转化成 N-k << N的情况。
而快速划分的算法本身决定了其复杂度和 k 的大小无关,所以当 k 接近 N/2 时,快速划分显然更优。
可是还有另一种情况,也是大公司面试的时候很可能会问到的题目:
给你200亿个整数,找出TOP500000。
第一次遇到这个问题,估计大多数人直接口突白沫了吧。
200亿,对一般PC而言,内存显然存不下,需要保存在辅存中,而辅存的IO速度。。。
所以你应该尽可能少地扫描。
于是这时候最小堆就是最优解决方案:只扫描一遍,就可以得出结果。
------
代码如下:
Jun
14
回忆一下tx的二面,有一道题是这样的:
假设有1kw个身份证号,以及他们对应的数据。身份证号可能重复,要求找出出现次数最多的身份证号。
一个很显然的做法是,hash之,O(n)搞定。这前提是内存中可以存下。
如果是中国的13亿人口,内存中存不下呢?借用磁盘,多次扫描?磁盘IO的速度慢得能让你疯掉。
这时候你终于感受到,中国人口真TMD多阿。。。
--
然后再看看今天的astar复赛第一题:
假设有1kw个身份证号,以及他们对应的数据。身份证号可能重复,要求找出出现次数最多的身份证号。
一个很显然的做法是,hash之,O(n)搞定。这前提是内存中可以存下。
如果是中国的13亿人口,内存中存不下呢?借用磁盘,多次扫描?磁盘IO的速度慢得能让你疯掉。
这时候你终于感受到,中国人口真TMD多阿。。。
--
然后再看看今天的astar复赛第一题:

